Being a Graphical Representation of
www.Paufler.net
www.paufler.net/brettwords
www.paufler.net/takosori
circa 2014 when the last two were seperate sites
Heck, after a title like that, I just might be all talked out...
Two Days
The NetworkX Library
and an
Intimate Understanding of Python
Yields
The Paufler Consortium of Websites Graphed Separately
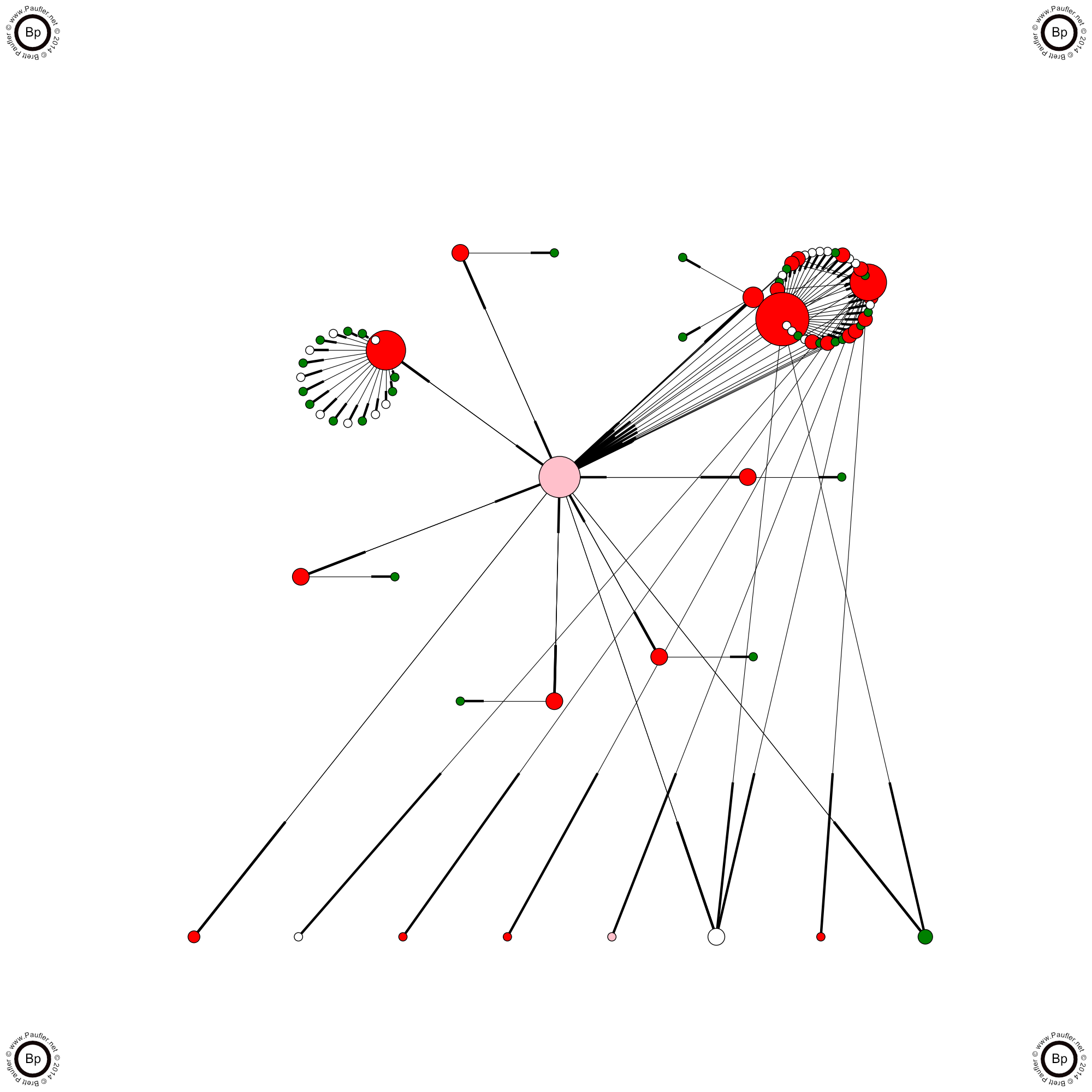
www.paufler.net/takosori Tarot Cards UFO's, & Such
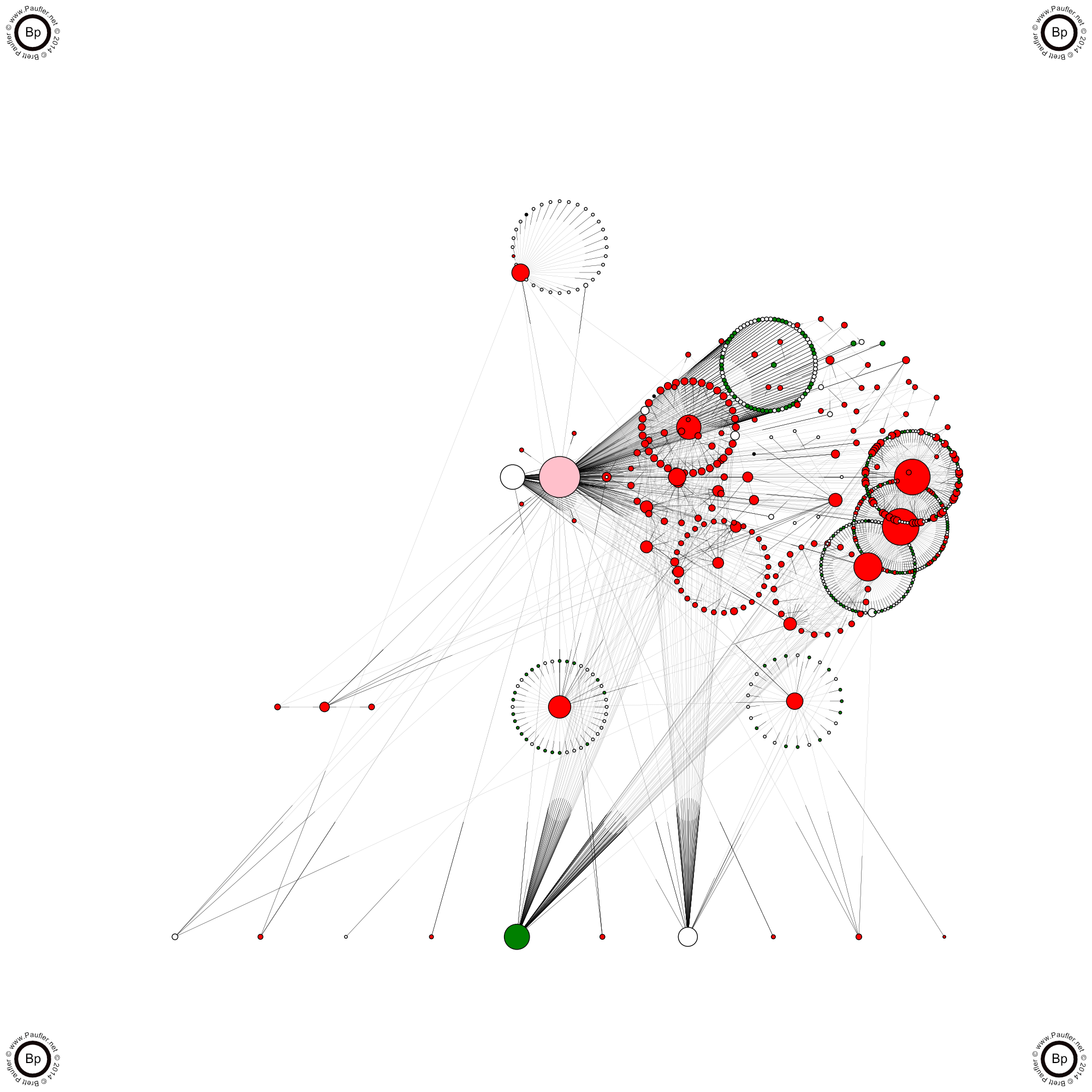
www.Paufler.net Only the Greatest Site on All the Webwww.paufler.net/brettwords Ah, Now, This This is Special
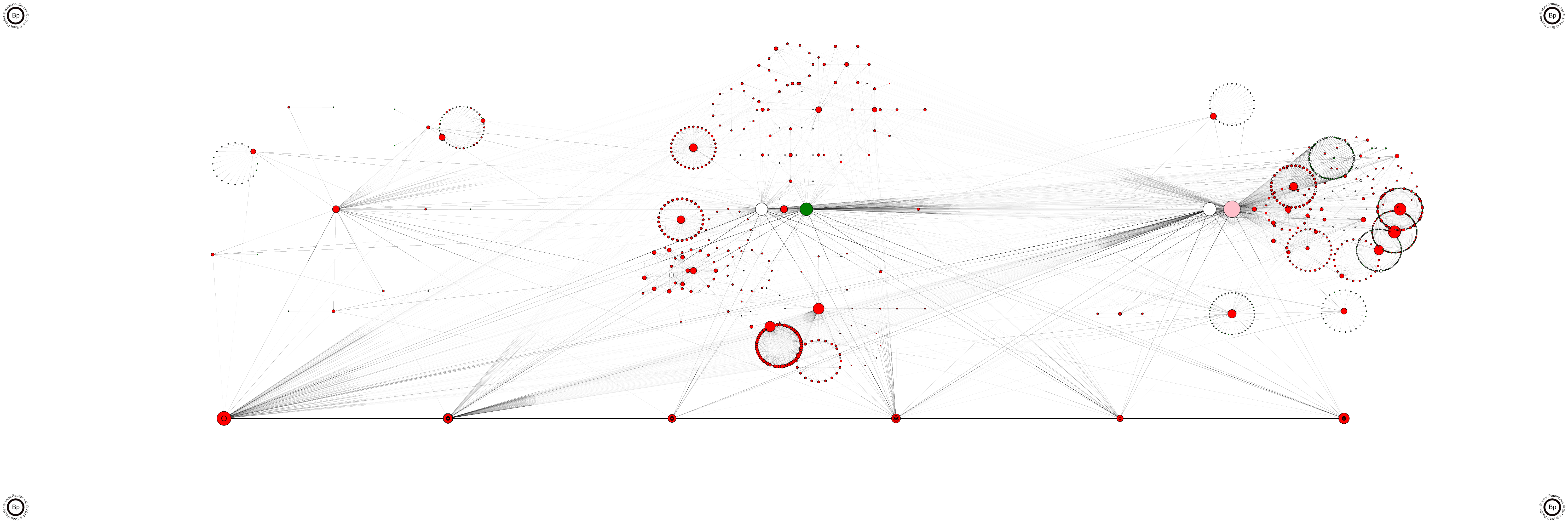
The Paufler Consortium of Websites Graphed Together
The Paufler Consortium Family of Websites
If One Picture is Worth a Thousand Words
I've Probably Written Enough Already
Actually, you got me as to whether you've found what you were looking for when you came to this page. This is just a side project in Graph Theory for me... a side project that led me to write a bit of code that jumps from html page to html page gathering together all the node links in a website... any website.
Well, OK. Not any website, not a dynamic php driven website powered by the likes of wordpress, but with any luck soon enough it will be.
The ironic part in all this (mere coincidence, I assure you) is that as I was debugging the code that powers the above (which means doing repeated scans of my sites in rapid succession), two of my sites were infected by some malicious code. Nothing too serious, just a few random links to points unknown for purposes unknown. Or, maybe you know the nefarious purpose and/or benefit that invisible links (white font, alpha set to zero) from a low ranked site (hey, I broke the 17 millionth mark in the world wide rankings last month) to other low ranked sites might garner anyone. Because, seriously, we all know it's not to booster anyone's search engine rankings, because (as you will see if you read on) if I can put together an algorithm that detects spurious links, you can bet Google and the rest have done the same thing years ago (and so invisible links count for squat in the rankings; or at least, they don't count for anything positive, so maybe someone's goal was to reduce the rank of every else's site on the web). But I digress, have gotten too wordy, and it is time to cut this short.
My link getter subroutine (of the inspirationally named GetLinks class) scans a html page and shoots back a list of links. Well, it's a small thing to add additional scans to that first; and the next thing you know, I've got myself a basic website malware detector, or whatever you want to call it.
And being in the scanning business for a week now, these are my thoughts:
Towards a Better Website Scanning Tool
or what to look for to determine if you site has been hacked
www.paufler.net/takosori A Simple Website
Track Outgoing Links
The Number #1 thing inserted into websites by malicious code is extraneous outgoing links. Don't ask me why they do this. The advantage is probably negligible. But it's easy to track them. In the picture above (and all the graphics on this page), outgoing links are displayed across the bottom. And not that I've implemented it yet, (but then, this page isn't so much about what I've implemented as much as it is a discussion of what I would want implemented in any scanning tool), comparing known outgoing links (safe links) to all outgoing links just isn't that hard. It's really just another link in a signature detection sub-loop.
Signature Detection & Malformed Code
In the end, code is just text (or binary; and then it's just 1's & 0's). And text can be scanned for content. Signature Detecting is simply scanning a document (text based or otherwise) for certain patterns. Say we know the string 'this_is_malicious_code' is associated with something undesirable. Well, then all we have to do is search all our web pages for 'this_is_malicious_code'; and if it appears, kick back an error message. It's not rocket science and it's not that hard to implement. The following being an adequate working template:
for web_page in list_of_web_pages:
for bad_code in list_of_bad_code_strings:
if bad_code in web_page:
post_error(bad_code, web_page)
The only trick in all that is making the signatures (the list_of_bad_code_strings) relevant. And believe it or not, the simplest way of doing that is by keeping one's code simple and then checking for the type of code malicious agents love but us simple folk have no need to use; and then, making a list of exceptions for when we absolutely have to use said spurious code:
for web_page in list_of_web_pages:
for bad_code in list_of_bad_code_strings:
if bad_code in web_page and not in exception_list:
post_error(bad_code, web_page)
And that's about what I had to say. I suppose I could give a short list of signatures, but I'm not going to. Suffice to say, that my html coding style is very simplistic (and getting more simplistic every day); and so, there is a whole WWW Spec Sheet full of tags, which I do not personally use. Thus, if any of those gimmicky (sophisticated, and/or advanced) tags are on my site, someone else put them there.
And then, the other side of the coin is that there is only so much I do with my site. I don't host pictures from other domains. And I very rarely place an outgoing link to, well, anywhere. In fact, if I had to guess, the same outgoing link accounts for very nearly 95% of my outgoing links (to the paperjs code library, just in case you were wondering).
So, anyway, if that's not all clear:
Scan for Signatures
code, tags, and words, you wouldn't use, or ones that are malformed (alpha zero, transparent, I'm looking for you)
Scan for Effects
things you wouldn't do (spurious links, i-Frames, raw eval, etc.)
Scan Raw Code and Resources
which really just means, know your site (look for foreign libraries and resources, both by name, but also what they are; yeah, that watermark, tells you and I both that these are my pictures, and it's easy enough to electronically check for same...)
And truthfully, at this point, I do believe that is all I have to say. Perhaps I will add an addendum to this page after I updated my scanner to include src links, along with javascript and php code snippet scanners. And then again, I just might not. One never can tell...